
P.S. you can get the sticker here:
https://www.redbubble.com/de/people/tamagothings/works/28066602-there-is-no-cloud?p=sticker
2,67 € for small
7,43 € for medium
11,13 € for large size
(prices include Euro VAT — I am not associated with sticker sales, just saving you the search)
People often argue “you get the elasticity” and the “extra bandwidth at spikes”, and a “rich toolkit to pick from” … as if this changes the fundamentals?
There can be good arguments for using someone else’s computer – you may possibly save some up-front capital and people expenses; but it comes at a price (you lose the control over it all, in every aspect) and one should very carefully compare the actual cost of cloud vs own when calculating ‘savings’.
- all your eggs are in one basket
- the basket is not yours: both the basket and your eggs are controlled by someone else
- you have to trust service availability (seems rock solid at first .. “too big to fail” ? — but every little admin mistake can bring you down along with everyone else – with little hope to be able to recover losses .. which you might otherwise have, with a decent SLA)
- you have to trust someone else’s cyber security measures
- you are a small part of a highly attractive target for the bad guys – and not just a (much smaller) target on your own merit
- you are at the total mercy of that someone else, if the business you bring no longer fits their model – example Google, example tumblr (have you ever tried migration from one cloud to another?)
- you can only use the toolset offered – should you require different functionality or tools: sorry, does not fit their business model, which is only re-active to the needs of many, many customers to make it worth their while
- you have zero control over latency – should you require different measures from what the lowest common denominator across all the cloud customers is, then the little business you bring to the cloud provider’s table is just too small for such extras (i.e. private BGP4 peering, and such)
- you DO have the cosy feeling of “everyone else does it, so I won’t get fired over a decision to go cloud” – but do you really want to be known for that Dilbert-like, middle manager image from the 1990s, when people made the same choices in favor of Microsoft products? And the Microsoft monopoly has since milked you how many times with new, expensive versions of the same stuff you had no choice in (migration to …?) and made you suffer very painfully for the lousy cyber security you automatically outsourced to them – bringing you many zero-days, phishing via VBS, crypto-locking malware, “patch Tuesdays” bi-weekly, disrupting your IT as if it is normal – and yet, you have not learned anything from it, and keep thinking today’s cloud business model is any different from Micro$oft’s in the old days? (hint: Microsoft also got big time into clouds … “Azure”, now increasingly running on Linux, like the rest of the cloud providers and the Internet)
- so: all this is worth how much in ‘savings’?
There is a reason why several big, and many medium-size business build their entire business model around it – they would not, unless it makes them a bunch of money (and that is money you think you are “saving” plus money made from using and selling your data). Example: AWS makes much more profit than the whole, huge retail empire – with a lot less effort. Should make you think :)
So while this sticker is meant to be funny, it does put the finger where it should hurt, too.
P.S.: of course, there are always alternatives – there is never just one, inevitable choice. If you have trouble thinking of those yourself, do some smart searches on the net; and you are welcome to talk to me about it.

https://de.statista.com/infografik/18231/cloud-vs-lokaler-speicher/
“As mentioned by Nicolas Marot, Google is currently having major service problems.
Snapchat (uses Google Cloud) is described as “Down” and there is a lot of red on the Google status dashboard.”- 04 JUN 2019




***

***
03 JUN 2019
50.000 Windows-Datenbank-Server mit Krypto-Minern infiziert
Vermeintlich chinesische Hacker haben weltweit Microsoft-SQL-Server- und PHPMyAdmin-Installationen mit versteckten Krypto-Miner-Skripten infiziert. Während sie damit Einheiten der Krypto-Währung Monero verdienten, kostete es die infizierten Server Rechenleistung und andere Ressourcen. Aufgedeckt hat das ganze die amerikanisch-israelische Sicherheitsfirma Guardicore Anfang April.

Über 50.000 Microsoft Windows SQL Datenbank-Server
über Uralt-Windows-Bug mit Krypto-Minern infiziert
Mit raffinierten Methoden haben Hacker zehntausende schlecht gesicherte Windows-Server gekapert und schürfen dort heimlich Monero.
Unbekannte Hacker, vermutlich aus China, infizieren momentan Microsoft-SQL-Server- und PHPMyAdmin-Installationen auf der ganzen Welt mit versteckten Krypto-Miner-Skripten. Die Opfer kostet das Rechenleistung und andere Ressourcen, die Angreifer verdienen sich heimlich Einheiten der Krypto-Währung Monero.
Während solche Angriffe gewöhnlicherweise mit relativ simplen, und damit vergleichsweise einfach zu entdeckenden, Methoden auskommen, zeichnen sich die aktuellen Angriffe durch ziemlich raffinierte Tricks aus. Unter anderem verwenden die Angreifer Malware, die mit einem gültigen Zertifikat signiert wurde und so unter dem Radar vieler automatischer Erkennungstechniken, unter anderem von Windows selbst, fliegt.
700 Server am Tag geknackt
Entdeckt wurden die Angriffe von der amerikanisch-israelischen Sicherheitsfirma Guardicore Anfang April. Seitdem konnten Sicherheitsforscher der Firma weitere Angriffsmuster ausmachen, die sie denselben Hackern zuordnen. Demnach sind diese seit mindestens Ende Februar aktiv und feilen seitdem kontinuierlich an ihren Angriffstechniken und der eingesetzten Malware.
Insgesamt konnten die Forscher bis zu 20 verschiedene Malware-Varianten ausmachen. Ihren Erkenntnissen nach infizieren die Hacker so bis zu 700 verschiedene Server am Tag. Die Sicherheitsforscher verschafften sich im Laufe ihrer Untersuchungen Zugang zu den Kontrollservern der Hacker und beziffern die Zahl der momentan infizierten Server auf knapp 50.000 Systeme.
Anscheinend haben die Hacker es auf Windows-Server abgesehen. Systeme im Gesundheitssektor, bei IT-Firmen, Telekommunikations-Dienstleistern und Medienunternehmen fielen den Angriffen bereits zum Opfer. Im ersten Schritt verschaffen sich die Hacker per Bruteforce-Angriff auf schwache Passwörter Zugang zum Microsoft SQL Server auf dem System. Dann nutzen sie den Zugang zum SQL Server, um ein VB-Skript zu erstellen und auszuführen, dass den Krypto-Miner auf dem System installiert, versteckt und ausführt.
Die Angreifer missbrauchen eine alte Schwachstelle im Windows-Kernel (CVE-2014-4113, von Microsoft im Oktober 2014 gepatcht), um System-Rechte für diesen Schritt zu erlangen. In einigen Fällen fand ein ähnlicher Angriff über schwache PHPMyAdmin-Passwörter, ebenfalls auf Windows, statt.
Gültiges Verisign-Zertifikat
Die Angreifer verankern ihre Mining-Malware mit Hilfe von Registry-Schlüsseln fest im System und installieren ein Rootkit, dass den Miner-Prozess überwacht und das System daran hindert, diesen zu beenden. Die Angreifer nutzen die Kernel-Schwachstelle mit einem Treiber aus, der zum Zeitpunkt des Angriffes ein gültiges Verisign-Zertifikat besaß, ausgestellt auf eine Firma namens Hangzhou Hootian Network Technology – bei dem Firmennamen handelt es sich um eine Fälschung. Das Zertifikat wurde nach einem Hinweis der Sicherheitsfirma mittlerweile von Verisign zurückgezogen und ist nun nicht mehr gültig.
Die Sicherheitsforscher vermuten auf Grund der chinesischen Fake-Firma und weil Teile des Malware-Codes in der proprietären, chinesischen Programmiersprache Easy Programming Language (EPL) geschrieben sind, dass die Angreifer aus dem Reich der Mitte stammen. Sie haben die Angriffsserie deswegen “Nansh0u” getauft. Diese Zeichenfolge kam in einer bei den Angriffen erstellten Datei vor – “nánshòu” ist Mandarin für “ungemütlich” oder “schwer zu ertragen”.
Leichtes Spiel mit ungepatchten Servern
Nansh0u verdeutlicht vor allem zwei Dinge: Es gibt im weltweiten Netz eine Menge von Windows-Servern mit uralten, ungepatchten Sicherheitslücken. Diese gefährden Systeme auch dann, wenn sie nicht direkt zum Einbruch in den Server missbraucht werden können, denn wo es uralte ungepatchte Lücken gibt, gibt es oft auch schwache Passwörter und ungenügenden Bruteforce-Schutz.
Außerdem zeigen die Angriffe, dass Krypto-Mining-Attacken nicht nur von Script Kiddies mit fertigen Exploit Kits durchgeführt werden, sondern auch von Angreifern, die sehr professionell vorgehen und viel Mühe in ihre Techniken stecken. Mit dem Schürfen von Monero lässt sich demnach noch genug Geld verdienen, um einen solchen Aufwand zu rechtfertigen. (fab)
Published 30 JUN 2019
***
03 JUN 2019
Im weiteren Zusammenhang (Zentralisierung, Globale Monopole):

Den entscheidenden Sachverhalt verschweigen uns die Strategen schamvoll: die Deutschland AG gehört nicht mehr den Deutschen. 85 Prozent des Dax befinden sich inzwischen in ausländischer Hand.
Nordamerikanische und britische Investoren halten derzeit 54,1 Prozent der Anteile an den 30 Dax-Unternehmen. Das enthüllt eine aktuelle Studie des Deutschen Investor Relations Verbands (DIRK).
► Die USA haben ihren Anteil an der Deutschland AG von 32,6 Prozent (2016) über 33,5 Prozent (2017) auf 34,6 Prozent (2018) ausgebaut und kaufen – auch angesichts der schwachen Kurse vieler ehemaliger Blue-Chips-Firmen – weiter zu.
► Der größte Einzelinvestor ursprünglich deutscher Vermögenswerte im Dax ist BlackRock mit 9,4 Prozent.
► Chinesische und andere asiatische Investoren spielen, anders als der mediale Alarmismus erwarten lässt, mit knapp vier Prozent nur eine untergeordnete Rolle.
via: Handelsblatt Daily
***
Those Machines In The Cloud
Cloud AI And The Future of Work

Artificial intelligence would be the ultimate version of Google. The ultimate search engine that would understand everything on the web. It would understand exactly what you wanted, and it would give you the right thing. We’re nowhere near doing that now. However, we can get incrementally closer to that, and that is basically what we work on.” — Larry Page
What happens when you take two fundamentally life changing technologies and merge them into an ultimate use case? The answer: businesses may become efficient but social disruption could become more prevalent. The argument for Universal Basic Income (UBI) becomes stronger as jobs get automated and vanish from the corporate landscape. However, all this is conjecture at this point. Big Tech firms are now offering Machine Learning (ML) tools on their respective clouds which allows corporate IT departments and novices to create ML applications without writing pieces of code to automate tasks. This article takes a look at a nascent boom in Research and Development (R&D) and new cloud AI platforms deployed by Google, Microsoft and Amazon. It concludes with a futuristic view of the employment landscape should these technologies succeed in creating ML Platforms as a Service (PaaS) for creating and deploying AI and ML applications.
Introduction To The Cloud
The cloud refers to the internet. Period. The internet began to be referred as a cloud because IT system diagrams would depict the internet using the cloud as a symbol. While the concept of the cloud is as old as the 1960’s with some attributing the idea to John McCarthy and others to JCR Licklider who enabled the development of ARPANET (pre-cursor to the modern internet). Irrespective of the attribution, the cloud was envisioned as a computer on the internet that would provide infrastructure such as storage, platforms such as operating systems and software applications over the internet for a fee. In a nutshell, it was conceived as renting hardware and/or software depending on the user’s requirement.
Subsequently, the launch of a Customer Relationship Management (CRM) software called ‘salesforce’ on the cloud which companies could license for a fee marked the beginning of the era of pervasive cloud computing. In fact, salesforce’s rai·son d’ê·tre. Subsequently, Amazon with the launch of the Elastic Compute Cloud which was a pay as you go cloud provided a further boost to popularization of the cloud. Today, Microsoft offers it’s cloud under the name Azure, Amazan under the name Amazon Web Services (AWS) and Google under Google Cloud Services.
As mentioned before, the cloud can host infrastructure as a service (IaaS), Platform as a Service (PaaS) and Software as a Service (SaaS). Also, the cloud can be a public (open to all on sharing basis) or a private cloud. Total market for global public cloud is estomated to be over $150 Billion in 2020.

Amazon, with its first mover advantage leads the pack in terms of global market share. Today, the market leader Amazon offers a plethora of solutions under AWS banner

Today, any business can be virtualized. What that means is that the backend becomes a service that can be rented from single or multiple providers.
A financial institution can be setup completely on the cloud and it can offer products via website and mobile apps. It could leverage networks such as the STAR network for issuance of ATM/Debit card. The Blockchain will become essential for accounting and facilitating cross border transactions. Banks can become completely digital without any brick and mortar architecture. However, that means the field would be ripe for big tech to enter and to leverage their network of users to build a loyal clientele.
Cloud computing has therefore spawned a revolution that is taking entire industries and virtualizing them. The next step is to look at human tasks that can be automated. This is where Artificial Intelligence (AI) residing on the cloud is key.
When AI Meets The Cloud
Now you know the cloud (internet, web 2.0 call it what you will) is everything today. However, challenges around 24/7 connectivity to the internet and cyber security still impede complete overhaul of IT systems across the world. That has not stopped technology companies for spending billions of dollars on research in AI. A deep learning revolution that began with Geoffrey Hinton’s back propagation is now being continued in the form of convolutional neural networks (CNN’s) and generative adversarial networks (GAN’s). The evolution in the approaches to machine learning is quite mind boggling. It’s like the torch is being passed from leader to the other across the world without any clear direction on who will emerge the likely winner. Till then, the battle rages on. The new arena is called Machine Learning as a Service (MLaaS).

There are tons of stories about how Microsoft, Google and Amazon are making ML accessible not only to data scientists but to common people as well. One of the most interesting stories is how Makoto, a farmer from Japan is using AI to cultivate cucumbers using Google’s TensorFlow opensource AI platform.
Microsoft Azure AI
Microsoft announced its cloud computing service on October 2008 and released it on February 1, 2010. Elektronische Fahrwerksysteme which develops Chassis for Audi uses Microsoft Azure to analyze roads. The idea is to enable autonomous vehicles think ahead and understand the roads they are on:
As part of its research efforts, the company used Azure NC-series virtual machines powered by NVIDIA Tesla P100 GPUs to drive a deep learning AI solution that analyzes high-resolution two-dimensional images of roads (source: Microsoft)
Ubisoft, a video game publisher, runs its eSports game, Rainbow Six Siege, in Microsoft Azure:
In 2016, Microsoft created what it called “the world’s first AI supercomputer” by installing Field-Programmable Gate Array (FPGA) across every Azure cloud server in 15 countries. As per wikipedia, an FPGA is an integrated circuit designed to be configured by customer or a designer after manufacturing — hence “field-programmable.
Google Cloud AutoML, Gluon, Tensorflow
Fei-Fei Li, Chief Scientist, Cloud AI at Google is trying to make machine learning accessible to all businesses. However, she also notes that very few corporations have the talent and other resources necessary to successfully embed AI into their business applications. To support it’s bid to gain and retain leadership in the Cloud AI space, Google opened up an entire ecosystem to developers which includes TensorFlow and Kubeflow as well as it’s container based system called Kubernetes.
Newspapers such as the Dainik Bhaskar (DB corp) group in India as well as Hearst group of publications utilizes Google Cloud AI to categorize digital content across it’s digital properties.
Amazon SageMaker
Amazon Sagemaker is a platform for developing and deploying deep learning applications. It was launched in November 2017. As per Amazon:
What Is Amazon SageMaker?
Amazon SageMaker is a fully managed machine learning service. With Amazon SageMaker, data scientists and developers can quickly and easily build and train machine learning models, and then directly deploy them into a production-ready hosted environment. It provides an integrated Jupyter authoring notebook instance for easy access to your data sources for exploration and analysis, so you don’t have to manage servers. It also provides common machine learning algorithms that are optimized to run efficiently against extremely large data in a distributed environment. With native support for bring-your-own-algorithms and frameworks, Amazon SageMaker offers flexible distributed training options that adjust to your specific workflows. Deploy a model into a secure and scalable environment by launching it with a single click from the Amazon SageMaker console. Training and hosting are billed by minutes of usage, with no minimum fees and no upfront commitments.
This is a HIPAA Eligible Service. For more information about AWS, U.S. Health Insurance Portability and Accountability Act of 1996 (HIPAA), and using AWS services to process, store, and transmit protected health information (PHI), see HIPAA Overview.
Are You a First-time User of Amazon SageMaker?
If you are a first-time user of Amazon SageMaker, we recommend that you do the following:
- Read How Amazon SageMaker Works – This section provides an overview of Amazon SageMaker, explains key concepts, and describes the core components involved in building AI solutions with Amazon SageMaker. We recommend that you read this topic in the order presented.
- Read Get Started – This section explains how to set up your account and create your first Amazon SageMaker notebook instance.
- Try a model training exercise – This exercise walks you through training your first model. You use training algorithms provided by Amazon SageMaker. For more information, see Get Started.
- Explore other topics – Depending on your needs, do the following:
- Submit Python code to train with deep learning frameworks – In Amazon SageMaker, you can use your own training scripts to train models. For information, see Use Machine Learning Frameworks with Amazon SageMaker.
- Use Amazon SageMaker directly from Apache Spark – For information, see Use Apache Spark with Amazon SageMaker.
- Use Amazon AI to train and/or deploy your own custom algorithms – Package your custom algorithms with Docker so you can train and/or deploy them in Amazon SageMaker. See Use Your Own Algorithms with Amazon SageMaker to learn how Amazon SageMaker interacts with Docker containers, and for the Amazon SageMaker requirements for Docker images.
- See the API Reference – This section describes the Amazon SageMaker API operations.more: https://docs.aws.amazon.com/sagemaker/latest/dg/whatis.html
Let’s take an example to understand how Amazon’s applications help integrate machine learning into everyday life.
Alex Schultz, a father with no deep learning experience built an application that reads books to his kids using Amazon Deep Lens called ReadtoMe. Alex built the application using opencv, Amazon Deeplens camera, python, polly, tesseract-ocr, lambda, mxnet and Google’s tensorflow. This example demonstrates the fact that ML is accessible and can be embedded in real life through a variety of applications which strengthens the argument that is may become all pervasive and ubiquitous.
Co-Opetition
On October 12, 2017, Amazon Web Services and Microsoft announced a new deep learning library, called Gluon, which allows developers of all skill levels to prototype, build, train and deploy sophisticated machine learning models for the cloud, devices at the edge and mobile apps.
AI is a very broad term that contains many building blocks such as the cloud platform, the programming platform, the API’s as well as the integrated circuits. Such a wide variety of inter-related and continuously evolving technologies with a wide array of applications in business and daily life provides big tech companies an edge. Who among them is the first among equals is for the future to say.
Future of Work
Every company is becoming a technology company. If not, they need to be aware of the mega trends and deploy resources wisely to prevent obsolescence.
Financial institutions today prefer to rent Software as a Service (SaaS) because developing software is not their core competency. Also, there is so much churn in technology today that being nimble and flexible is key to survival and growth.
Imagine a scenario where you wanted a certain sales report or a business review prepared for senior leadership. You could just give a voice command to a digital assistant (AI) to give you a year to date national report of all sales during 2018. The data would be stored on the same cloud as the AI assistant is. The AI bot would then organize data and send it to an output of your choice which could be an augmented reality screen. Now, extend this scenario to all routine and non routine tasks that can be automated and you can imagine how scary AI as a technology can be. It is like technology just gobbled the world of work as we know it.
At first, routine tasks can be automated. Later, AI can become a recommendation engine and finally it will be able to take decisions on its own. There are varying estimates on the extent of automation in the next decade or so. However, the takeaway for most is that learning new skills or treating life as a continuing education should be the mantra.

While technological disruption is continuing its march into the workplace, AI and its effects are not pervasive enough to cause social unrest. Yet. Therein lies the ethical dilemma.
For instance, politicians in developing economies such as India are already hearing distressed voices complaining about the loss of driving jobs due to automated vehicles. When an automated Uber killed a pedestrian in Arizona, the incident gave rise to suspicions around the viability of automation. As with Bitcoin, CRISPR CAS 9 Genetic Editing technology, AI regulation will need to be ahead of the game.
However, for common folk like us, learning just acquired a whole new practical meaning.
from: https://hackernoon.com/those-machines-in-the-cloud-c988f36b6bef
***
Human-level performance in 3D multiplayer games with population-based reinforcement learning
Science 31 May 2019:
Vol. 364, Issue 6443, pp. 859-865
DOI: 10.1126/science.aau6249

End-to-end reinforcement learning (RL) methods (1–5) have so far not succeeded in training agents in multiagent games that combine team and competitive play owing to the high complexity of the learning problem that arises from the concurrent adaptation of multiple learning agents in the environment (6, 7). We approached this challenge by studying team-based multiplayer three-dimensional (3D) first-person video games, a genre that is particularly immersive for humans (8) and has even been shown to improve a wide range of cognitive abilities (9). We focused specifically on a modified version (10) of Quake III Arena (11), the canonical multiplayer 3D first-person video game, whose game mechanics served as the basis for many subsequent games and which has a thriving professional scene (12).
The task we considered is the game mode Capture the Flag (CTF), which is played on both indoor- and outdoor-themed maps that are randomly generated for each game (Fig. 1, A and B). Two opposing teams consisting of multiple individual players compete to capture each other’s flags by strategically navigating, tagging, and evading opponents. The team with the greatest number of flag captures after five minutes wins. The opposing teams’ flags are situated at opposite ends of each map—a team’s base—and in indoor-themed maps, the base room is colored according to the team color. In addition to moving through the environment, agents can tag opponents by activating their laser gadget when pointed at an opponent, which sends the opponent back to their base room after a short delay, known as respawning. If an agent is holding a flag when they are tagged, this flag is dropped to the floor where they are tagged and is said to be stray. CTF is played in a visually rich simulated physical environment (movie S1), and agents interact with the environment and with other agents only through their observations and actions (moving forward and backward; strafing left and right; and looking by rotating, jumping, and tagging). In contrast to previous work (13–23), agents do not have access to models of the environment, state of other players, or human policy priors, nor can they communicate with each other outside of the game environment. Each agent acts and learns independently, resulting in decentralized control within a team.

(A and B) Two example maps that have been sampled from the distribution of (A) outdoor maps and (B) indoor maps. Each agent in the game sees only its own first-person pixel view of the environment. (C) Training data are generated by playing thousands of CTF games in parallel on a diverse distribution of procedurally generated maps and (D) used to train the agents that played in each game with RL. (E) We trained a population of 30 different agents together, which provided a diverse set of teammates and opponents to play with and was also used to evolve the internal rewards and hyperparameters of agents and learning process. Each circle represents an agent in the population, with the size of the inner circle representing strength. Agents undergo computational evolution (represented as splitting) with descendents inheriting and mutating hyperparameters (represented as color). Gameplay footage and further exposition of the environment variability can be found in movie S1.
Learning system
We aimed to devise an algorithm and training procedure that enables agents to acquire policies that are robust to the variability of maps, number of players, and choice of teammates and opponents, a challenge that generalizes that of ad hoc teamwork (24). In contrast to previous work (25), the proposed method is based purely on end-to-end learning and generalization. The proposed training algorithm stabilizes the learning process in partially observable multiagent environments by concurrently training a diverse population of agents who learn by playing with each other. In addition, the agent population provides a mechanism for meta-optimization.
In our formulation, the agent’s policy π uses the same interface available to human players. It receives raw red-green-blue (RGB) pixel input xt from the agent’s first-person perspective at time step t, produces control actions at ~ π(⸱|x1, …, xt) by sampling from the distribution given by policy π, and receives ρt, game points, which are visible on the in-game scoreboard. The goal of RL in this context is to find a policy that maximizes the expected cumulative reward Eπ[∑Tt=1rt]
over a CTF game with T time steps. We used a multistep actor-critic policy gradient algorithm (2) with off-policy correction (26) and auxiliary tasks (5) for RL. The agent’s policy π was parameterized by means of a multi–time scale recurrent neural network with external memory (Fig. 2A and fig. S11) (27). Actions in this model were generated conditional on a stochastic latent variable, whose distribution was modulated by a more slowly evolving prior process. The variational objective function encodes a trade-off between maximizing expected reward and consistency between the two time scales of inference (28). Whereas some previous hierarchical RL agents construct explicit hierarchical goals or skills (29–32), this agent architecture is conceptually more closely related to work outside of RL on building hierarchical temporal representations (33–36) and recurrent latent variable models for sequential data (37, 38). The resulting model constructs a temporally hierarchical representation space in a way that promotes the use of memory (fig. S7) and temporally coherent action sequences.
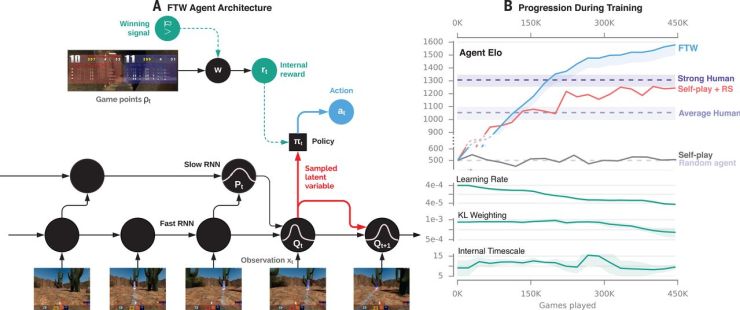
(A) How the agent processes a temporal sequence of observations xt from the environment. The model operates at two different time scales, faster at the bottom and slower by a factor of τ at the top. A stochastic vector-valued latent variable is sampled at the fast time scale from distribution Qt
on the basis of observations xt. The action distribution πt is sampled conditional on the latent variable at each time step t. The latent variable is regularized by the slow moving prior Pt, which helps capture long-range temporal correlations and promotes memory. The network parameters are updated by using RL according to the agent’s own internal reward signal rt, which is obtained from a learned transformation w of game points ρt. w is optimized for winning probability through PBT, another level of training performed at yet a slower time scale than that of RL. Detailed network architectures are described in fig. S11. (B) (Top) The Elo skill ratings of the FTW agent population throughout training (blue) together with those of the best baseline agents by using hand-tuned reward shaping (RS) (red) and game-winning reward signal only (black), compared with human and random agent reference points (violet, shaded region shows strength between 10th and 90th percentile). The FTW agent achieves a skill level considerably beyond strong human subjects, whereas the baseline agent’s skill plateaus below and does not learn anything without reward shaping [evaluation procedure is provided in (28)]. (Bottom) The evolution of three hyperparameters of the FTW agent population: learning rate, Kullback-Leibler divergence (KL) weighting, and internal time scale τ, plotted as mean and standard deviation across the population.
For ad hoc teams, we postulated that an agent’s policy π1 should maximize the probability P(π1‘s team wins|ω,π1:N)
of winning for its team, π1:N2=(π1,π2,…πN2), which is composed of π1 itself, and its teammates’ policies π2,…,πN2, for a total of N players in the game
(1)in which trajectories τ (sequences of actions, states, and rewards) are sampled from the joint probability distribution pπ1:Nω
over game setup ω and actions sampled from policies. The operator 𝟙[x] returns 1 if and only if x is true, and ⚐(τ, π) returns the number of flag captures obtained by agents in π in trajectory τ. Ties are broken by ϵ, which is sampled from an independent Bernoulli distribution with probability 0.5. The distribution Ω over specific game setups is defined over the Cartesian product of the set of maps and the set of random seeds. During learning and testing, each game setup ω is sampled from Ω, ω ~ Ω. The final game outcome is too sparse to be effectively used as the sole reward signal for RL, and so we learn rewards rt to direct the learning process toward winning; these are more frequently available than the game outcome. In our approach, we operationalized the idea that each agent has a dense internal reward function (39–41) by specifying rt = w(ρt) based on the available game points signals ρt (points are registered for events such as capturing a flag) and, crucially, allowing the agent to learn the transformation w so that policy optimization on the internal rewards rt optimizes the policy “For The Win,” giving us the “FTW agent.”
Training agents in multiagent systems requires instantiations of other agents in the environment, such as teammates and opponents, to generate learning experience. A solution could be self-play RL, in which an agent is trained by playing against its own policy. Although self-play variants can prove effective in some multiagent games (14, 15, 42–46), these methods can be unstable and in their basic form do not support concurrent training, which is crucial for scalability. Our solution is to train in parallel a population of P different agents π=(πp)Pp=1
that play with each other, introducing diversity among players in order to stabilize training (47). Each agent within this population learns from experience generated by playing with teammates and opponents sampled from the population. We sampled the agents indexed by ι for a training game by using a stochastic matchmaking scheme mp(π) that biases co-players to be of similar skill to player p. This scheme ensures that—a priori—the outcome is sufficiently uncertain to provide a meaningful learning signal and that a diverse set of teammates and opponents participate in training. Agents’ skill levels were estimated online by calculating Elo scores [adapted from chess (48)] on the basis of outcomes of training games. We also used the population to meta-optimize the internal rewards and hyperparameters of the RL process itself, which results in the joint maximization of
Jinner(πp|wp)=Eι∼mp(π),ω∼ΩEτ∼pπtω[∑t=1Tγt−1wp(ρp,t)]∀πp∈π
Jouter(wp,ϕp|π)=Eι∼mp(π),ω∼ΩP(πw,ϕp‘s team wins∣∣ω,πw,ϕι)
(2)
πw,ϕp=optimizeπp(Jinner,w,ϕ)
This can be seen as a two-tier RL problem. The inner optimization maximizes Jinner, the agents’ expected future discounted internal rewards. The outer optimization of Jouter can be viewed as a meta-game, in which the meta-reward of winning the match is maximized with respect to internal reward schemes wp and hyperparameters ϕp, with the inner optimization providing the meta transition dynamics. We solved the inner optimization with RL as previously described, and the outer optimization with population-based training (PBT) (49). PBT is an online evolutionary process that adapts internal rewards and hyperparameters and performs model selection by replacing underperforming agents with mutated versions of better agents. This joint optimization of the agent policy by using RL together with the optimization of the RL procedure itself toward a high-level goal proves to be an effective and potentially widely applicable strategy and uses the potential of combining learning and evolution (50) in large-scale learning systems.
Tournament evaluation
To assess the generalization performance of agents at different points during training, we performed a large tournament on procedurally generated maps with ad hoc matches that involved three types of agents as teammates and opponents: ablated versions of FTW (including state-of-the-art baselines), Quake III Arena scripted bots of various levels (51), and human participants with first-person video game experience. The Elo scores and derived winning probabilities for different ablations of FTW, and how the combination of components provide superior performance, are shown in Fig. 2B and fig. S1. The FTW agents clearly exceeded the win-rate of humans in maps that neither agent nor human had seen previously—that is, zero-shot generalization—with a team of two humans on average capturing 16 fewer flags per game than a team of two FTW agents (fig. S1, bottom, FF versus hh). Only as part of a human-agent team did we observe a human winning over an agent-agent team (5% win probability). This result suggests that trained agents are capable of cooperating with never-seen-before teammates, such as humans. In a separate study, we probed the exploitability of the FTW agent by allowing a team of two professional games testers with full communication to play continuously against a fixed pair of FTW agents. Even after 12 hours of practice, the human game testers were only able to win 25% (6.3% draw rate) of games against the agent team (28).
Interpreting the difference in performance between agents and humans must take into account the subtle differences in observation resolution, frame rate, control fidelity, and intrinsic limitations in reaction time and sensorimotor skills (fig. S10A) [(28), section 3.1]. For example, humans have superior observation and control resolution; this may be responsible for humans successfully tagging at long range where agents could not (humans, 17% tags above 5 map units; agents, 0.5%). By contrast, at short range, agents have superior tagging reaction times to humans: By one measure, FTW agents respond to newly appeared opponents with a mean of 258 ms, compared with 559 ms for humans (fig. S10B). Another advantage exhibited by agents is their tagging accuracy, in which FTW agents achieve 80% accuracy compared with humans’ 48%. By artificially reducing the FTW agents’ tagging accuracy to be similar to humans (without retraining them), the agents’ win rate was reduced though still exceeded that of humans (fig. S10C). Thus, although agents learned to make use of their potential for better tagging accuracy, this is only one factor contributing to their overall performance.
To explicitly investigate the effect of the native superiority in the reaction time of agents compared with that of humans, we introduced an artificial 267-ms reaction delay to the FTW agent (in line with the previously reported discrepancies, and corresponding to fast human reaction times in simple psychophysical paradigms) (52–54). This response-delayed FTW agent was fine-tuned from the nondelayed FTW agent through a combination of RL and distillation through time [(28), section 3.1.1]. In a further exploitability study, the human game testers achieved a 30% win rate against the resulting response-delayed agents. In additional tournament games with a wider pool of human participants, a team composed of a strong human and a response-delayed agent could only achieve an average win rate of 21% against a team of entirely response-delayed agents. The human participants performed slightly more tags than the response-delayed agent opponents, although delayed agents achieved more flag pickups and captures (Fig. 2). This highlights that even with more human-comparable reaction times, the agent exhibits human-level performance.
Agent analysis
We hypothesized that trained agents of such high skill have learned a rich representation of the game. To investigate this, we extracted ground-truth state from the game engine at each point in time in terms of 200 binary features such as “Do I have the flag?”, “Did I see my teammate recently?”, and “Will I be in the opponent’s base soon?” We say that the agent has knowledge of a given feature if logistic regression on the internal state of the agent accurately models the feature. In this sense, the internal representation of the agent was found to encode a wide variety of knowledge about the game situation (fig. S4). The FTW agent’s representation was found to encode features related to the past particularly well; for example, the FTW agent was able to classify the state “both flags are stray” (flags dropped not at base) with 91% AUCROC (area under the receiver operating characteristic curve), compared with 70% with the self-play baseline. Looking at the acquisition of knowledge as training progresses, the agent first learned about its own base, then about the opponent’s base, and then about picking up the flag. Immediately useful flag knowledge was learned before knowledge related to tagging or their teammate’s situation. Agents were never explicitly trained to model this knowledge; thus, these results show the spontaneous emergence of these concepts purely through RL-based training.
A visualization of how the agent represents knowledge was obtained by performing dimensionality reduction of the agent’s activations through use of t-distributed stochastic neighbor embedding (t-SNE) (Fig. 3) (55). Internal agent state clustered in accordance with conjunctions of high-level game-state features: flag status, respawn state, and agent location (Fig. 3B). We also found individual neurons whose activations coded directly for some of these features—for example, a neuron that was active if and only if the agent’s teammate was holding the flag, which is reminiscent of concept cells (56). This knowledge was acquired in a distributed manner early in training (after 45,000 games) but then represented by a single, highly discriminative neuron later in training (at around 200,000 games). This observed disentangling of game state is most pronounced in the FTW agent (fig. S8).

(A) The 2D t-SNE embedding of an FTW agent’s internal states during gameplay. Each point represents the internal state (hp, hq) at a particular point in the game and is colored according to the high-level game state at this time—the conjunction of (B) four basic CTF situations, each state of which is colored distinctly. Color clusters form, showing that nearby regions in the internal representation of the agent correspond to the same high-level game state. (C) A visualization of the expected internal state arranged in a similarity-preserving topological embedding and colored according to activation (fig. S5). (D) Distributions of situation conditional activations (each conditional distribution is colored gray and green) for particular single neurons that are distinctly selective for these CTF situations and show the predictive accuracy of this neuron. (E) The true return of the agent’s internal reward signal and (F) the agent’s prediction, its value function (orange denotes high value, and purple denotes low value). (G) Regions where the agent’s internal two–time scale representation diverges (red), the agent’s surprise, measured as the KL between the agent’s slow– and fast–time scale representations (28). (H) The four-step temporal sequence of the high-level strategy “opponent base camping.” (I) Three automatically discovered high-level behaviors of agents and corresponding regions in the t-SNE embedding. (Right) Average occurrence per game of each behavior for the FTW agent, the FTW agent without temporal hierarchy (TH), self-play with reward shaping agent, and human subjects (fig. S9).
One of the most salient aspects of the CTF task is that each game takes place on a randomly generated map, with walls, bases, and flags in new locations. We hypothesized that this requires agents to develop rich representations of these spatial environments in order to deal with task demands and that the temporal hierarchy and explicit memory module of the FTW agent help toward this. An analysis of the memory recall patterns of the FTW agent playing in indoor environments shows precisely that; once the agent had discovered the entrances to the two bases, it primarily recalled memories formed at these base entrances (Fig. 4 and fig. S7). We also found that the full FTW agent with temporal hierarchy learned a coordination strategy during maze navigation that ablated versions of the agent did not, resulting in more efficient flag capturing (fig. S2).

Shown is the development of knowledge representation and behaviors of the FTW agent over the training period of 450,000 games, segmented into three phases (movie S2). “Knowledge” indicates the percentage of game knowledge that is linearly decodable from the agent’s representation, measured by average scaled AUCROC across 200 features of game state. Some knowledge is compressed to single-neuron responses (Fig. 3A), whose emergence in training is shown at the top. “Relative internal reward magnitude” indicates the relative magnitude of the agent’s internal reward weights of 3 of the 13 events corresponding to game points ρ. Early in training, the agent puts large reward weight on picking up the opponent’s flag, whereas later, this weight is reduced, and reward for tagging an opponent and penalty when opponents capture a flag are increased by a factor of two. “Behavior probability” indicates the frequencies of occurrence for 3 of the 32 automatically discovered behavior clusters through training. Opponent base camping (red) is discovered early on, whereas teammate following (blue) becomes very prominent midway through training before mostly disappearing. The “home base defense” behavior (green) resurges in occurrence toward the end of training, which is in line with the agent’s increased internal penalty for more opponent flag captures. “Memory usage” comprises heat maps of visitation frequencies for (left) locations in a particular map and (right) locations of the agent at which the top-10 most frequently read memories were written to memory, normalized by random reads from memory, indicating which locations the agent learned to recall. Recalled locations change considerably throughout training, eventually showing the agent recalling the entrances to both bases, presumably in order to perform more efficient navigation in unseen maps (fig. S7).
Analysis of temporally extended behaviors provided another view on the complexity of behavioral strategies learned by the agent (57) and is related to the problem a coach might face when analyzing behavior patterns in an opponent team (58). We developed an unsupervised method to automatically discover and quantitatively characterize temporally extended behavior patterns, inspired by models of mouse behavior (59), which groups short game-play sequences into behavioral clusters (fig. S9 and movie S3). The discovered behaviors included well-known tactics observed in human play, such as “waiting in the opponents base for a flag to reappear” (“opponent base camping”), which we only observed in FTW agents with a temporal hierarchy. Some behaviors, such as “following a flag-carrying teammate,” were discovered and discarded midway through training, whereas others such as “performing home base defense” are most prominent later in training (Fig. 4).
Conclusions
In this work, we have demonstrated that an artificial agent using only pixels and game points as input can learn to play highly competitively in a rich multiagent environment: a popular multiplayer first-person video game. This was achieved by combining PBT of agents, internal reward optimization, and temporally hierarchical RL with scalable computational architectures. The presented framework of training populations of agents, each with their own learned rewards, makes minimal assumptions about the game structure and therefore could be applicable for scalable and stable learning in a wide variety of multiagent systems. The temporally hierarchical agent represents a powerful architecture for problems that require memory and temporally extended inference. Limitations of the current framework, which should be addressed in future work, include the difficulty of maintaining diversity in agent populations, the greedy nature of the meta-optimization performed by PBT, and the variance from temporal credit assignment in the proposed RL updates. Our work combines techniques to train agents that can achieve human-level performance at previously insurmountable tasks. When trained in a sufficiently rich multiagent world, complex and surprising high-level intelligent artificial behavior emerged.
Supplementary Materials
science.sciencemag.org/content/364/6443/859/suppl/DC1
Supplementary Text
Figs. S1 to S12
Pseudocode
Supplementary Data
Movies S1 to S4
http://www.sciencemag.org/about/science-licenses-journal-article-reuse
This is an article distributed under the terms of the Science Journals Default License.
References and Notes
Author contributions: M.J. and T.Gra. conceived and managed the project; M.J., W.M.C., and I.D. designed and implemented the learning system and algorithm with additional help from L.M., T.Gra., G.L., N.S., T.Gre., and J.Z.L.; A.G.C., C.B., and L.M. created the game environment presented; M.J., W.M.C., I.D., and L.M. ran experiments and analyzed data with additional input from N.C.R., A.S.M., and A.R.; L.M. and L.D. ran human experiments; D.S., D.H., and K.K. provided additional advice and management; M.J., W.M.C., and T.Gra. wrote the paper; and M.J. and W.M.C. created figures and videos.
Competing interests: M.J., W.M.C., and I.D. are inventors on U.S. patent application US62/677,632 submitted by DeepMind that covers temporally hierarchical RL. M.J., W.M.C., and T.G. are inventors on U.S. patent application PCT/EP2018/082162 submitted by DeepMind that covers population based training of neural networks. I.D. is additionally affiliated with Hudson River Trading, New York, NY, USA.
Data and materials availability: A full description of the algorithm in pseudocode is available in the supplementary materials. The data are deposited in 10.7910/DVN/JJETYE (60).
You must be logged in to post a comment.